I modelli AI non sono intercambiabili.
I modelli AI non sono intercambiabili
Per mesi sono caduto nella trappola di pensare che aggiornare un agente AI fosse semplice come cambiare una chiamata API. Bastava puntare a un modello più recente, no?
La realtà mi ha dato torto più volte di quante vorrei ammettere. Ho visto agenti che funzionavano perfettamente in staging andare in pezzi in produzione dopo un banale cambio di versione del framework. Piccole modifiche a un LLM o a un adattatore alteravano silenziosamente il comportamento dell’intero sistema, e me ne accorgevo solo quando un cliente segnalava qualcosa di strano.
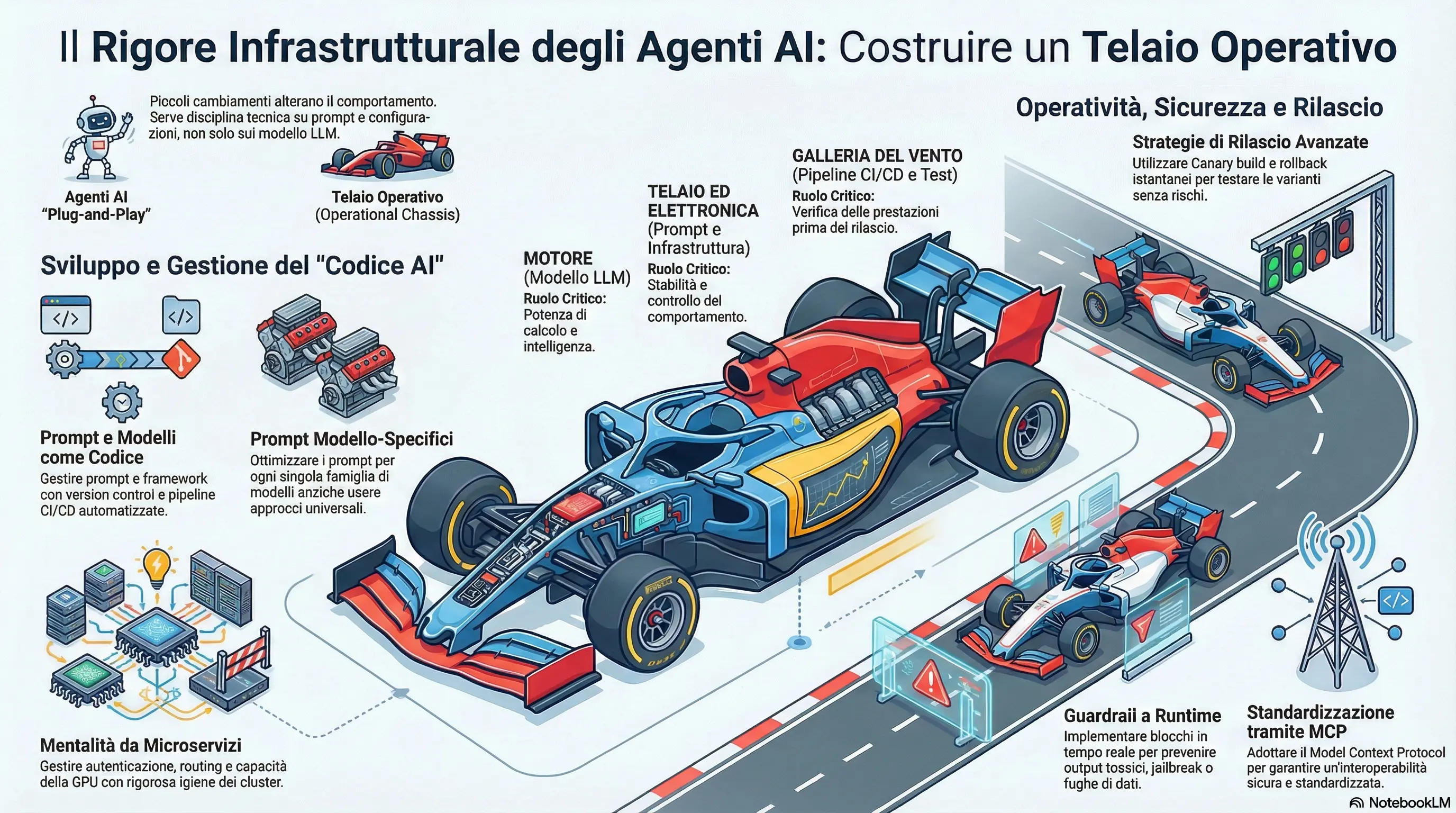
Con il tempo ho capito una cosa fondamentale: in produzione serve rigore infrastrutturale. Bisogna trasformare gli agenti da prototipi fragili a software robusto.
1. Ho imparato a trattare i prompt come codice
All’inizio tenevo i prompt in file di testo sparsi, qualcuno nel database, qualcuno in un Google Doc. Un disastro. Dopo aver perso ore a ricostruire “quale versione del prompt funzionava ieri”, ho cambiato approccio:
- Version Control: Ora ogni modifica al prompt è tracciata in Git, come qualsiasi altro pezzo di codice.
- Pipeline CI/CD: Nessun prompt va in produzione senza passare attraverso la pipeline. Ho imparato questa lezione a mie spese.
- Test di Regressione: Prima di ogni rilascio, testo il nuovo prompt contro compiti noti per assicurarmi che non abbia perso capacità precedenti. Mi è capitato di migliorare un caso d’uso e romperne tre.
2. Non esiste il “modello universale”
Uno degli errori più costosi che ho commesso è stato scambiare i modelli (passare da GPT-4 a Claude, per esempio) aspettandomi che tutto funzionasse magicamente. Non funziona così. Ciò che è ottimale per un modello potrebbe essere un disastro per un altro.
Ora mantengo rami di sviluppo dedicati per ogni famiglia di modelli e adatto i prompt prima del passaggio effettivo. Sembra un lavoro extra, ma mi ha risparmiato notti insonni.
3. Canary e rollback: rilasciare senza farsi male
Il comportamento degli agenti è non deterministico, quindi ho smesso di fare rilasci “big bang”. Ecco cosa faccio adesso:
- Canary Builds: Rilascio la nuova versione solo a una piccola percentuale di traffico e confronto le tracce per rilevare anomalie.
- Rollback Istantanei: Mi assicuro sempre di poter tornare alla versione precedente in pochi secondi. Questa capacità mi ha salvato più di una volta.
4. Sicurezza e standardizzazione con MCP
Ho capito presto che reinventare la ruota per far parlare gli agenti tra loro è una pessima idea. L’adozione del Model Context Protocol (MCP) mi ha permesso di far interoperare gli agenti in modo sicuro, attraverso “API che gli agenti possono capire”. E ho imparato a non fidarmi mai ciecamente dell’output: i guardrail a runtime per bloccare jailbreak, tossicità o fughe di dati personali sono diventati parte integrante di ogni mio deploy.
5. La mentalità DevOps applicata all’AI
Una delle lezioni più importanti che ho maturato è questa: gran parte del lavoro per rendere un agente pronto per la produzione non riguarda l’intelligenza artificiale in sé. Riguarda autenticazione, routing, capacità della GPU e igiene dei cluster. In pratica, ho dovuto applicare tutto ciò che sapevo sui microservizi a questi nuovi sistemi.
L’analogia che uso sempre Immaginate di gestire una scuderia di Formula 1. Non potete semplicemente sostituire il motore con uno più potente (il nuovo modello LLM) e aspettarvi di vincere. Dovete ricalibrare l’elettronica, i freni e il telaio (l’infrastruttura) e testare tutto in galleria del vento (CI/CD). Senza questo “telaio operativo”, rischiate solo un guasto spettacolare alla prima curva. Ecco, io quel guasto l’ho vissuto, e non voglio ripeterlo.
Dopo mesi di lavoro sul campo, la mia convinzione è questa: creare agenti sostenibili dipende meno dalla ricerca del modello perfetto e più dalla costruzione di un sistema che gestisca il non-determinismo con disciplina tecnica. Ho smesso di “giocare” con i prompt e ho iniziato a fare ingegneria. Vi consiglio di fare lo stesso.

